
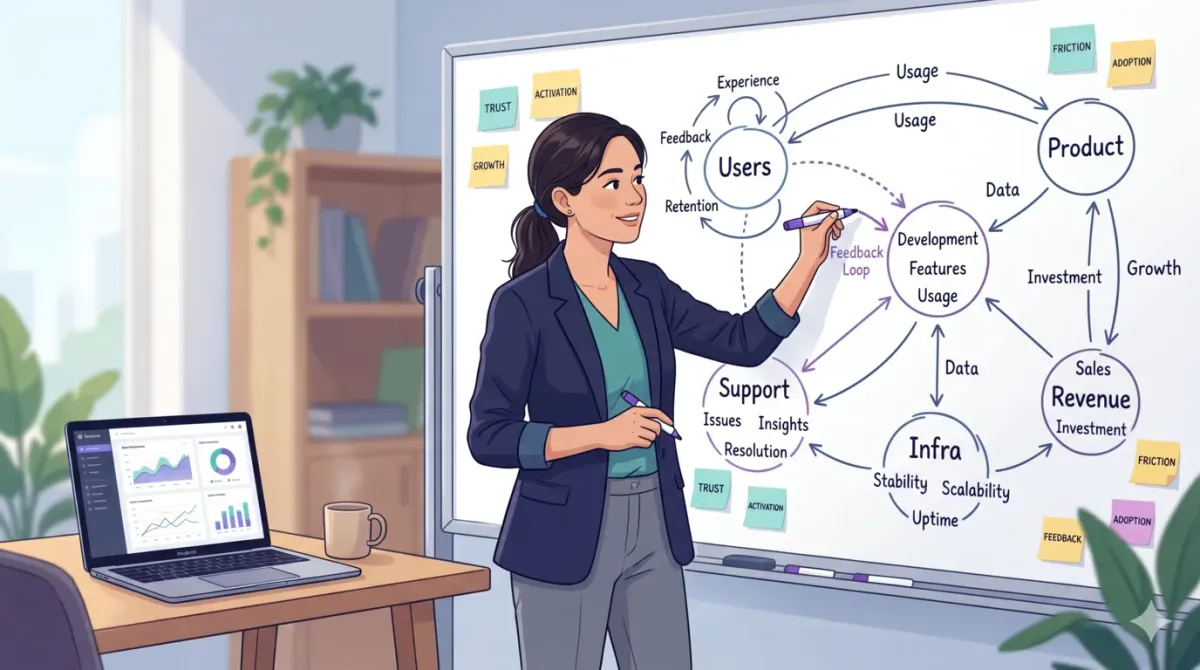
You’ve probably lived through some version of this.
You push a small change live on a Friday evening — a cleaner onboarding flow that removes one “unnecessary” step. Activation looks better in the first few days.
Signups are flowing in. The dashboard screenshot looks great in the Monday stand-up.
Then the weirdness starts.
Support tickets slowly creep up:
“I’m confused after step 2.”
“Where do I find X now?”
Sales starts complaining that new leads feel colder. Infra notices a spike in a part of the system nobody touched. A month later, your retention chart looks slightly worse, not better — and nobody can quite agree why.
On paper, you shipped a good UX improvement. In reality, you poked a system.
The more products I see, the more I realise this is normal. Features don’t live alone. They live inside loops: users, teams, incentives, infrastructure, and money all reacting to each other over time.
That’s where systems thinking comes in. It’s the difference between “we shipped what was in the PRD” and “we understood what we were doing to the whole product.”
What is systems thinking? (For PMs, in simple words)
If you search “what is systems thinking”, you’ll find dense definitions from universities and leadership blogs.
For product managers, we don’t need a textbook definition. We need something we can use in a PRD or a roadmap review.
Here’s the version that’s worked best for me:
Systems thinking is a way of understanding your product where you focus on relationships and feedback loops, not just individual features or events.
Instead of:
- “Feature A will increase Metric B.”
You start thinking:
- “Feature A will change how users behave, how support works, how infra is stressed, how sales sells, and how trust evolves — and those changes will come back to us later.”
Once you see your product as a living system like this, you stop expecting clean, linear outcomes… and you start designing for how things actually behave in the wild.
Why product managers need systems thinking right now
Look at where most products live today:
- They depend on platforms (Apple, Google, Meta) that change rules whenever they want.
- They’re fighting for attention on crowded devices.
- They’re built by cross-functional teams with misaligned incentives.
- They’re now layered with AI, which adds new behaviour and new failure modes.
If you keep thinking in straight lines — “we’ll ship X and metric Y will go up” — you’ll keep getting surprised:
- Growth experiments that pump signups but tank user quality.
- UX “simplifications” that quietly overload support.
- Pricing tweaks that look great in a spreadsheet but distort behaviour and trust.
- Shortcuts that create tech debt and slow everything down in 6–12 months.
A lot of leadership content around “why you need systems thinking now” basically says: quick wins that ignore the wider system create hidden risk that explodes later.
In PM language: systems thinking is how you ship work that ages well, not just work that screenshots well.
Systems thinking vs normal product thinking
Let’s put this side by side.
Normal product thinking:
- Roadmap = list of features and epics.
- Success = local metric moves (activation rate, CTR on a specific button, MRR this quarter).
- Feedback = dashboards + weekly reports + some user interviews.
Systems thinking as a PM:
- Roadmap = list of system interventions (trust loop, performance loop, acquisition loop, monetisation loop).
- Success = how the whole product system behaves over time, not just one metric in isolation.
- Feedback = metrics, user stories, operational data, and how other teams are affected (support, infra, sales, finance).
The mindset shift:
- From “How do I ship X?”
- To “What system am I changing, which loops am I feeding, and what will that do over the next 3–6–12 months?”
If you read my Notion breakdown How Notion Became a $10B Product With Zero Ads, you’ll see this everywhere — they didn’t win through isolated tricks; they built a system that reinforced itself.
Core systems thinking concepts (in PM language)
You don’t need to memorise academic frameworks.
You need a few lenses that fit into how you already work as a PM.
Systems and boundaries
A system is just: components + relationships + purpose.
For most products, components are things like:
- Users, admins, sales, marketing, success, support, infra, finance
- The data and events flowing between them
- The mission or business model that defines “success”
The trap is how we draw boundaries.
If you quietly decide “our system is just the app and this squad”, you instantly ignore:
- Sales behaviour
- Support workload
- Infra and reliability
- Legal / compliance / procurement
- Finance targets and constraints
Every PRD silently chooses a boundary.
A good self-check: “Who did I conveniently ignore when I wrote this?”
Interconnectedness and interdependence
In a real product, nothing moves alone.
Change pricing and you’ll feel it in:
- Who signs up
- How they use the product
- How sales pitches the value
- How infra gets loaded
- How support conversations change
Simplify onboarding and:
- You reduce drop-offs, yes
- But you might also invite more low-intent signups who never activate and generate noise
Add one more step to guard against fraud and:
- You protect the system
- But maybe you frustrate your best users who now have extra friction
Systems thinking is the habit of asking: “If this goes exactly as planned, what else will it change?”
The answer usually lives outside your team’s metric.
Feedback loops: reinforcing and balancing
A feedback loop is when something in the system affects itself in the future.
Two types matter most for us:
- Reinforcing loops (flywheels)
- More users → more content → more value → more users.
- Or: more notifications → more short-term engagement → more notifications → long-term fatigue.
- Balancing loops (brakes / stabilisers)
- More tickets → team improves self-serve help → fewer tickets.
- Gains in performance → infra costs rise → budgets push you to optimise.
Whenever I review a roadmap now, I ask:
- “Which reinforcing loop does this feature feed?”
- “Which balancing loop is going to push back if we succeed?”
The Notion case study is basically me reverse-engineering their reinforcing loops and how they avoided killing them with bad short-term decisions.
Delays and nonlinearity
Systems don’t follow sprint timelines.
There are delays between what we do and what we see.
You’ve probably seen patterns like:
- You cut support headcount. Nothing breaks for a bit. Then response times slowly increase, NPS drifts down, and churn shows up later.
- You push hard discounts. MRR spikes. Months later, people don’t convert without a discount; perceived value is lower.
And they’re usually nonlinear:
- Traffic is fine, traffic is fine, traffic is fine… then you hit some hidden limit and latency explodes.
- Notifications are “tolerated” until they’re suddenly muted across the board.
If you’re staring at a chart that’s flat and then suddenly cliffs or spikes, ask:
“What delay or threshold did we ignore in this system?”
Emergence: when the system surprises you
Emergence is when the whole system behaves in a way no single part predicted.
In product land, this is:
- A small reaction feature that accidentally becomes the main way people communicate.
- A “hidden” power-user workflow that spreads through communities and changes how your product is used.
- A share button that ends up driving half your organic growth.
Instead of thinking “users are weird”, systems thinking says:
“The system is telling us something; we just didn’t design for it on purpose.”
Weird usage patterns are feedback, not bugs in user intelligence.
Leverage points: small changes, big effects
A leverage point is a spot in the system where a small tweak creates a big outcome.
For PMs, these often look like:
- Defaults (opt-in vs opt-out)
- Incentives (what sales/CS are rewarded for)
- Guardrails and access rules
- How and where information is surfaced (dashboards, alerts, in-product hints)
Example:
- Flipping one notification from “on by default” to “off by default” can improve long-term trust more than building a whole new engagement feature.
Our job isn’t just to ship more stuff.
It’s to find leverage points so we can ship less stuff and get better outcomes.
Mental models I actually use for systems thinking
“Mental models in systems thinking” sounds fancy; in practice I lean on a small set again and again.
Here are the ones that show up in my product work:
- Second-order effects – if this works, then what happens next? And after that?
- Compounding / decay – small improvements or cuts that slowly stack.
- Local vs global optima – the team’s metric vs what’s good for the whole product/company.
- Goodhart’s law – “when a measure becomes a target, it stops being a good measure.”
- Tragedy of the commons – shared resources (infra, support, user attention) get overused if nobody protects them.
I’ll often paste a short list of these into PRDs for risky bets.
Even just seeing those words forces better discussion.
Product scenarios where systems thinking changes the call
Let’s go from theory to day-to-day PM life.
Scenario 1: The “successful” growth campaign that tanks user quality
Linear move:
- “We need more signups. Add a referral/cashback offer. If signups go up, win.”
System view:
- Incentive attracts deal-seekers, not your ideal users.
- Support load grows, fraud risk goes up, infra gets hammered.
- Sales wastes time on low-quality accounts; churn rises later.
Systems-thinking move:
- Map who earns, who pays, and who does the work.
- Decide upfront what “good new user” means.
- Add constraints and checks to favour long-term fit, not just raw signup count.
Scenario 2: The notification that quietly kills trust
Linear move:
- “DAU is flat. Let’s send a push whenever X happens. More touches, more engagement.”
System view:
- User attention is a shared, limited resource.
- Overdoing pings → users mute or disable them → you lose direct communication.
- Some uninstall; ratings wobble; future launches underperform because the channel is burnt.
Systems-thinking move:
- Treat notifications as part of a trust loop, not an engagement hack.
- Define rules: what’s critical, what’s nice-to-have, what should be silent.
- Track long-term mute/uninstall behaviour, not just short-term click-through.
Scenario 3: Pricing tweak with weird downstream effects
Linear move:
- “Raise mid-tier prices. Graph shows higher MRR. Done.”
System view:
- Some customers downgrade, some churn, some start using you in a different way.
- Sales has harder conversations, changes positioning.
- Infra cost per customer might go up or down depending on who stays.
Systems-thinking move:
- Simulate across multiple dimensions: revenue, churn, user mix, sales cycle, infra cost, support load.
- Run smaller or time-boxed tests before you lock in a global change.
Scenario 4: Tiny UX change, big support headache
Linear move:
- “This step feels extra. Remove it. Fewer steps = better UX.”
System view:
- That step was doing work: setting expectations, qualifying users, educating.
- Remove it and confusion moves downstream: more “how do I…?” tickets, more misconfigured accounts.
Systems-thinking move:
- Ask: “What job was that step doing in the system?”
- If you remove a step, make sure its job shows up somewhere else (empty states, tooltips, lifecycle emails, docs).
How to apply systems thinking in your day-to-day PM work
Reading is nice.
Systems thinking only sticks when it shows up in how you spend time.
Before you build: do a 20‑minute system map
For any meaningful change, take 15–20 minutes to sketch the system:
- Actors: users, admins, sales, marketing, success, support, infra, finance.
- Flows: data, money, work, attention, trust, risk.
- Constraints: performance limits, budgets, policies, team capacity.
Then ask:
- “Who ends up doing more work if this goes well?”
- “Who ends up paying more (money, time, risk)?”
- “What am I assuming stays constant?”
It doesn’t need to be pretty.
Even a rough whiteboard is an upgrade over “user clicks button, sees success state.”
During discovery: turn feature requests into system problems
In discovery, people throw solutions at you all day:
- “Add filters.”
- “Send a reminder.”
- “Add a tooltip.”
Instead of arguing solutions, I try to understand:
- “What system is producing this pain?”
- “Is this really a UX problem, or is it incentives, policy, or process?”
Example:
- “Low feature usage” might be a discoverability problem.
- Or a packaging problem (wrong plan).
- Or a misaligned incentive (CS pushes a different workflow because that’s in their playbook).
Reframing like this is how you stop shipping bandaids and start adjusting the underlying system.
While roadmapping: group by loops, not just features
Most roadmaps are grouped by:
- Areas: “Onboarding, Messaging, Admin, Billing”
- Teams: “Core, Growth, Platform”
Try adding another view: which loop does this touch?
- Trust and safety
- Performance and reliability
- Acquisition and virality
- Activation and habit formation
- Monetisation and expansion
You’ll quickly see:
- Where you’re over-optimising one loop (e.g., too many growth hacks).
- Which loops you’ve been ignoring (e.g., reliability or trust).
- A clearer story for leadership: “This quarter, we’re deliberately shoring up the trust and performance loops.”
This fits nicely with the architecture thinking I walk through in System Design Basics Every Product Leader Needs — you’re designing flows and behaviour, not just endpoints.
During experiments: track side effects on purpose
When I run experiments now, I don’t stop at “primary metric + success threshold”.
I also define:
- Guardrail metrics – things that must not get worse (support volume, latency, complaint types).
- Leading indicators of system stress – error spikes, angry power-user feedback, escalation volume.
Questions I like:
- “If the main metric goes up, how could this still be a bad idea?”
- “Which team should we proactively check with before rolling this out to 100%?”
This is one reason I care about SQL for PMs.
Dashboards usually show local metrics. SQL lets you peek behind them and see how the system behaves across tables, segments, and time. That’s why I wrote SQL for Product Managers: Only Guide You’ll Actually Use.
After launch: run systems retros, not blame retros
When something goes wrong, most teams start with “who messed up?”
A systems retro starts with:
- “How did our system make this outcome likely?”
- “What information or feedback were we missing at the time?”
- “Which incentives or constraints nudged us this way?”
Often the fixes are boring but powerful:
- Better alerts
- A simple guardrail or limit
- A clearer approval path
- Slightly different KPIs
You still hold people accountable, but you also fix the environment so the mistake is less likely to repeat.
My systems thinking checklist for PMs (steal this)
Here’s a checklist I’d happily paste into a PRD template.
Before shipping a big bet, ask:
- System: What system am I changing (who, what flows, what constraints)?
- Loops: Which reinforcing and balancing loops does this touch?
- Delays: When will the impact really show up (days, weeks, months)?
- Side effects: If the main metric improves, what could still go wrong?
- Shared resources: Whose time, attention, or infra are we spending?
- Incentives: Whose incentives improve and whose get worse?
If this lens resonates, you’ll probably also like AI Tools for Product Managers: The Ones I Use Daily — that post is basically about building a personal system around time, attention, and leverage, not just stacking tools.
A 7‑day systems thinking workout for PMs
If you want this to stick, you need reps, not more reading.
Here’s a simple 7‑day workout:
- Day 1–2: Pick one recent launch. Map the system: actors, flows, constraints, feedback loops.
- Day 3–4: Take one key metric (say, activation). Write three reinforcing loops and three balancing loops around it.
- Day 5–6: Take a roadmap item and list five possible side effects if it works exactly as expected.
- Day 7: Share one system map with your team and ask, “What did I miss?”
You’ll notice your brain starting to default to “system view” much faster after doing this a few times.
FAQ: systems thinking for product managers
What is systems thinking in simple words?
Systems thinking is a way of understanding your product where you focus on how things connect and influence each other, not just on isolated screens or events.
What is a systems thinking approach in product management?
It’s when you design changes to a system — loops, incentives, flows — instead of only thinking in features. You ask “what system are we changing?” before “what should we build?”
What does systems thinking mean in business?
In business, systems thinking means seeing your company as a network of teams, processes, markets, and incentives that interact over time, instead of as separate silos.
What are mental models in systems thinking?
They’re simple ways of thinking (like feedback loops, second-order effects, Goodhart’s law) that help you understand how your product system behaves and where to intervene.
Why do product managers need systems thinking now?
Because your product is more connected and fragile than ever — across teams, tools, regulations, and AI-driven user expectations — and shallow optimisations create hidden risks that blow up later.
If you want to go deeper into this, check out:
- System Design Basics Every Product Leader Needs – to connect this mindset with real architectural decisions.
- How Notion Became a $10B Product With Zero Ads – a real system analysis in the wild.
- SQL for Product Managers: Only Guide You’ll Actually Use – if you want better visibility into how your system behaves in data.
This article + those three posts together become a nice “systems stack” for PMs who want to think and build at a higher level.

Comments