
In the vast digital landscape, search engines act as the gateway to information, enabling users to access a wealth of knowledge with a simple search query.
Have you ever wondered how search engines navigate the vast web and collect relevant data to provide accurate search results?
The answer lies in the intricate process called website crawling.
In this article, we will delve into the fascinating world of website crawling, exploring the technology that powers this essential function of search engines.
What is Website Crawling?
Before we dive into the technology behind website crawling, let’s understand what it means.
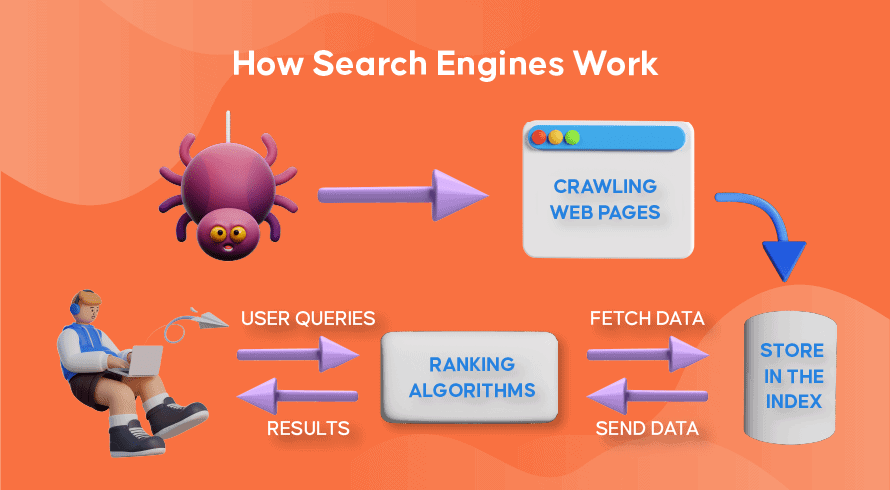
Website crawling, also known as web crawling or spidering, is the automated process by which search engines discover and analyze web pages to build their index.
Crawlers, also referred to as spiders or bots, are software programs that systematically browse the web, following links from one page to another.
Web Crawlers: The Workhorses of Search Engines
Web crawlers are the backbone of search engines, tirelessly scanning the internet to gather information.
They start by fetching a list of URLs to visit, commonly referred to as the “seed URLs.”
These seeds URLs can be either submitted by website owners or discovered through previous crawls or sitemaps.
The Technology behind Web Crawlers
Web crawlers employ various technologies and techniques to crawl websites efficiently. Let’s explore some of the key components:
HTTP Requests and Responses
When a web crawler encounters a URL, it sends an HTTP request to the web server hosting the website. The server responds with an HTTP response, which contains the web page’s HTML content.
The crawler then processes the HTML to extract valuable information and follows the links found within the page.
Example: Imagine a web crawler, let’s call it “CrawlerBot,” visits a popular news website. It sends an HTTP request to the server asking for the homepage.
The server responds with an HTTP response containing the HTML of the homepage.
CrawlerBot analyzes the HTML, extracts the headlines and article URLs, and follows those URLs to continue its crawling journey.
Parsing HTML and Extracting Data
To extract useful information from web pages, crawlers rely on HTML parsing.
HTML parsing involves analyzing the structure and content of HTML documents to identify key elements like headings, paragraphs, images, and links.
Example: Suppose CrawlerBot encounters an article page during its crawl.
It parses the HTML, identifies the article’s title, author, publication date, and main content.
It also extracts any embedded images and hyperlinks to other relevant pages.
Link Analysis and Discovery
One of the primary goals of web crawling is to discover new pages and follow relevant links to expand the search engine’s index.
Crawlers use algorithms to analyze the links found on each page and decide which ones to follow.
These algorithms prioritize links that are more likely to lead to valuable content.
Example: As CrawlerBot parses a webpage, it discovers multiple links embedded within the content. It uses link analysis algorithms to determine which links to follow.
For instance, it may prioritize links from reputable sources or those that match the user’s search intent more closely.
Handling Dynamic Content
With the rise of dynamic websites powered by JavaScript frameworks, crawlers face the challenge of properly rendering and analyzing web pages that rely heavily on client-side scripting.
Modern web crawlers employ techniques like headless browsers and JavaScript rendering engines to overcome this hurdle. These tools can execute JavaScript code and capture the fully rendered content.
Example: If CrawlerBot encounters a website built with a popular JavaScript framework like React or Angular, it uses a headless browser like Puppeteer or a JavaScript rendering engine like Chromium to fully render the page, ensuring it captures the dynamic content generated by the JavaScript code.
Crawling Etiquette: Robots.txt and Crawling Policies
Search engines respect the guidelines set by website owners through a file called “robots.txt.”
This file, located at the root of a website, specifies which parts of the site should not be crawled.
Website owners can also define crawl rate limits to prevent excessive crawling and server overload.
Example:
Let’s say CrawlerBot arrives at a website and discovers a robots.txt file. It reads the file and adheres to the rules set by the website owner, ensuring it only crawls the allowed pages and respects the crawl rate limits.
Final Words
Website crawling is a fundamental process that drives the functionality of search engines, enabling them to index vast amounts of information from across the web.
Through the use of sophisticated technologies like HTTP requests, HTML parsing, link analysis, and handling dynamic content, web crawlers meticulously traverse the internet to gather valuable data.
Understanding the technology behind website crawling provides insight into how search engines function, delivering accurate search results and connecting users with the information they seek.
As the web continues to evolve, web crawlers will adapt and incorporate new technologies to ensure the indexing process remains efficient and effective.


